(스마트인재개발원) Kaggle대회 참가 - 전자 상거래 물품 배송 예측(분류)

ID: ID 고객 번호입니다.
창고 블록: 회사에는 A,B,C,D,E와 같은 블록으로 나누어진 큰 창고가 있습니다.
배송 모드:회사는 제품을 선박, 비행 및 도로와 같은 다양한 방법으로 배송합니다.
고객 관리 전화: 발송물 조회를 위한 문의로 걸려온 전화 수.
고객 등급: 그 회사는 모든 고객들로부터 등급을 매겼다. 1이 가장 낮음(최악), 5가 가장 높음(최악)입니다.
제품 비용: 제품 비용(미국 달러)
이전 구매: 이전 구입 횟수입니다.
제품 중요도: 회사는 제품을 저, 중, 고 등 다양한 파라미터로 분류했습니다.
성별: 남성과 여성.
할인 혜택: 그 특정 제품에 대한 할인이 제공됩니다.
가중치: 그것은 그램 단위의 무게이다.
정시에 도달함: 이 값은 목표 변수입니다. 여기서 1 제품이 제시간에 도달하지 못했음을 나타내고 0은 제시간에 도달했음을 나타냅니다.
1. 원-핫 인코딩(One-Hot Encoding)이란?
원-핫 인코딩은 단어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식입니다. 이렇게 표현된 벡터를 원-핫 벡터(One-Hot vector)라고 합니다.
원-핫 인코딩을 두 가지 과정으로 정리해보겠습니다.
(1) 각 단어에 고유한 인덱스를 부여합니다. (정수 인코딩)
(2) 표현하고 싶은 단어의 인덱스의 위치에 1을 부여하고, 다른 단어의 인덱스의 위치에는 0을 부여합니다.
1) 선형 서포트 벡터
(1) 서포트 벡터
서포트 벡터를 설명하기에 앞서 마진(Margin) 에 대해서 먼저 알아보자.
마진(Margin) 이란 클래스를 구분하는 초평면(결정 경계)과 가장 가까운 훈련 샘플 사이의 거리를 의미한다. 아래 그림에서 점선부분이 이에 해당한다.

1) Gaussian Naive Bayes Classifier
Bayes theorem은 두 확률 변수 A,BA,B 사이의 관계를 이용해 P(A|B)P(A|B)를 구하는 방법에 관한 theorem입니다.
식으로 살펴보자면, 다음과 같습니다.
A1∪A2=AA1∪A2=A이고 A1∩A2=∅A1∩A2=∅이면서 A⊃BA⊃B일때,
P(A1|B)=P(B∩A1P(B)P(A1|B)=P(B∩A1P(B)
=P(B|A1)P(A1)P(B)=P(B|A1)P(A1)P(B)
=P(B|A1)P(A1)P(B|A1)P(A1)+P(B|A2)P(A2)
예측값을 계산하는 경우는 키가 주어진 상태에서 그 사람이 남자일 확률 또는 여자일 확률을 구하는 것이기 때문에 우리가 구하고자 하는 값은 P(A1|B)P(A1|B)와 P(A2|B)P(A2|B)입니다. 하지만 P(A1∩B)P(A1∩B)나 P(A2∩B)P(A2∩B)와 같은 값을 쉽게 구할 수 있을까? training data를 이용해서 구할 수 있는 확률의 종류에는 한계가 있다 더군다나 확률변수 BB가 취할 수 있는 값이 연속적일 경우
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
train['Customer_care_calls']= train['Customer_care_calls'].fillna(3)
test['Customer_care_calls']= test['Customer_care_calls'].fillna(3)
train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6999 entries, 0 to 6998
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ID 6999 non-null int64
1 Warehouse_block 6999 non-null object
2 Mode_of_Shipment 6999 non-null object
3 Customer_care_calls 6999 non-null float64
4 Customer_rating 6999 non-null int64
5 Cost_of_the_Product 6999 non-null int64
6 Prior_purchases 6049 non-null float64
7 Product_importance 6999 non-null object
8 Gender 6999 non-null object
9 Discount_offered 3468 non-null float64
10 Weight_in_gms 6999 non-null object
11 Reached.on.Time_Y.N 6999 non-null int64
dtypes: float64(3), int64(4), object(5)
memory usage: 656.3+ KB
train.columns
Index(['ID', 'Warehouse_block', 'Mode_of_Shipment', 'Customer_care_calls',
'Customer_rating', 'Cost_of_the_Product', 'Prior_purchases',
'Product_importance', 'Gender', 'Discount_offered', 'Weight_in_gms',
'Reached.on.Time_Y.N'],
dtype='object')
idx_nm_1 = train[train['Cost_of_the_Product'] == 9999].index
train = train.drop(idx_nm_1, axis=0)
train['Prior_purchases'] = train['Prior_purchases'].fillna(3.5)
test['Prior_purchases'] = test['Prior_purchases'].fillna(3.5)
train.drop('Discount_offered', axis=1, inplace=True)
test.drop('Discount_offered', axis=1, inplace=True)
# train['Discount_offered'] = train['Discount_offered'].fillna(13.2)
# test['Discount_offered'] = test['Discount_offered'].fillna(13.2)
train['Mode_of_Shipment'].unique()
array([' Ship', ' Flight', ' Road', '?', ' Shipzk', ' Flightzk',
' Roadzk'], dtype=object)
test['Mode_of_Shipment'].unique()
array([' Ship', ' Flight', '?', ' Road', ' Shipzk', ' Roadzk'],
dtype=object)
train.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 6996 entries, 0 to 6998
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ID 6996 non-null int64
1 Warehouse_block 6996 non-null object
2 Mode_of_Shipment 6996 non-null object
3 Customer_care_calls 6996 non-null float64
4 Customer_rating 6996 non-null int64
5 Cost_of_the_Product 6996 non-null int64
6 Prior_purchases 6996 non-null float64
7 Product_importance 6996 non-null object
8 Gender 6996 non-null object
9 Weight_in_gms 6996 non-null object
10 Reached.on.Time_Y.N 6996 non-null int64
dtypes: float64(2), int64(4), object(5)
memory usage: 655.9+ KB
test['Mode_of_Shipment']= test['Mode_of_Shipment'].replace(' Ship', 'Ship')
test['Mode_of_Shipment']= test['Mode_of_Shipment'].replace(' Flight', 'Flight')
test['Mode_of_Shipment']= test['Mode_of_Shipment'].replace(' Road', 'Road')
test['Mode_of_Shipment']= test['Mode_of_Shipment'].replace('?', 'Ship')
test['Mode_of_Shipment']= test['Mode_of_Shipment'].replace(' Shipzk', 'Ship')
test['Mode_of_Shipment']= test['Mode_of_Shipment'].replace(' Flightzk', 'Flight')
test['Mode_of_Shipment']= test['Mode_of_Shipment'].replace(' Roadzk', 'Road')
train['Mode_of_Shipment']= train['Mode_of_Shipment'].replace(' Ship', 'Ship')
train['Mode_of_Shipment']= train['Mode_of_Shipment'].replace(' Flight', 'Flight')
train['Mode_of_Shipment']= train['Mode_of_Shipment'].replace(' Road', 'Road')
train['Mode_of_Shipment']= train['Mode_of_Shipment'].replace('?', 'Ship')
train['Mode_of_Shipment']= train['Mode_of_Shipment'].replace(' Shipzk', 'Ship')
train['Mode_of_Shipment']= train['Mode_of_Shipment'].replace(' Flightzk', 'Flight')
train['Mode_of_Shipment']= train['Mode_of_Shipment'].replace(' Roadzk', 'Road')
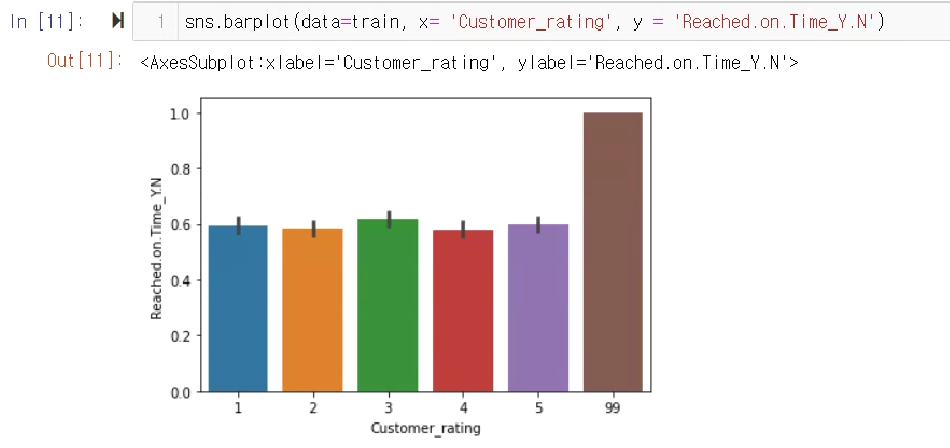
train['Customer_rating'].unique()
array([ 2, 3, 1, 5, 4, 99], dtype=int64)
train['Customer_rating']= train['Customer_rating'].replace(99, 3)
test['Customer_rating']= test['Customer_rating'].replace(99, 3)
train['Product_importance'].value_counts()
low 3344
medium 2979
high 573
? 97
mediumm 1
loww 1
highh 1
Name: Product_importance, dtype: int64
train['Product_importance']= train['Product_importance'].replace('mediumm', 'medium')
train['Product_importance']= train['Product_importance'].replace('loww', 'low')
train['Product_importance']= train['Product_importance'].replace('highh', 'high')
train['Product_importance']= train['Product_importance'].replace('?', 'medium')
test['Product_importance']= test['Product_importance'].replace('mediumm', 'medium')
test['Product_importance']= test['Product_importance'].replace('loww', 'low')
test['Product_importance']= test['Product_importance'].replace('highh', 'high')
test['Product_importance']= test['Product_importance'].replace('?', 'medium')
train['Product_importance'].unique()
array(['low', 'medium', 'high'], dtype=object)
train['Weight_in_gms']= train['Weight_in_gms'].replace('?', 0)
test['Weight_in_gms']= test['Weight_in_gms'].replace('?', 0)
train['Weight_in_gms'] = pd.to_numeric(train['Weight_in_gms'])
test['Weight_in_gms'] = pd.to_numeric(test['Weight_in_gms'])
train['Weight_in_gms'].mean()
3423.673956546598
train['Weight_in_gms']= train['Weight_in_gms'].replace(0, 3634)
test['Weight_in_gms']= test['Weight_in_gms'].replace(0, 3634)
train['Weight_in_gms']= train['Weight_in_gms']
test['Weight_in_gms']= test['Weight_in_gms'].replace(0, 3634)
train.drop(columns=["ID"],axis=1,inplace=True)
test.drop(columns=["ID"],axis=1,inplace=True)
train.drop("Gender",axis=1,inplace=True)
test.drop("Gender",axis=1,inplace=True)
train = pd.get_dummies(train, columns=['Warehouse_block', 'Product_importance','Mode_of_Shipment','Customer_rating','Prior_purchases'], drop_first=True)
test = pd.get_dummies(test, columns=['Warehouse_block','Product_importance', 'Mode_of_Shipment','Customer_rating','Prior_purchases'], drop_first=True)
con_data= train[['Weight_in_gms', "Cost_of_the_Product"]]
con_data2= test[['Weight_in_gms', "Cost_of_the_Product"]]
# con_data= train[["Customer_care_calls","Cost_of_the_Product","Discount_offered","Weight_in_gms"]]
# con_data2= test[["Customer_care_calls","Cost_of_the_Product","Discount_offered","Weight_in_gms"]]
train[['Weight_in_gms',"Cost_of_the_Product"]] = StandardScaler().fit_transform(con_data)
test[['Weight_in_gms',"Cost_of_the_Product"]] = StandardScaler().fit_transform(con_data2)
X=train.drop(['Reached.on.Time_Y.N'], axis=1)
y=train['Reached.on.Time_Y.N']
X.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 6996 entries, 0 to 6998
Data columns (total 23 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Customer_care_calls 6996 non-null float64
1 Cost_of_the_Product 6996 non-null float64
2 Weight_in_gms 6996 non-null float64
3 Warehouse_block_B 6996 non-null uint8
4 Warehouse_block_C 6996 non-null uint8
5 Warehouse_block_D 6996 non-null uint8
6 Warehouse_block_F 6996 non-null uint8
7 Product_importance_low 6996 non-null uint8
8 Product_importance_medium 6996 non-null uint8
9 Mode_of_Shipment_Road 6996 non-null uint8
10 Mode_of_Shipment_Ship 6996 non-null uint8
11 Customer_rating_2 6996 non-null uint8
12 Customer_rating_3 6996 non-null uint8
13 Customer_rating_4 6996 non-null uint8
14 Customer_rating_5 6996 non-null uint8
15 Prior_purchases_3.0 6996 non-null uint8
16 Prior_purchases_3.5 6996 non-null uint8
17 Prior_purchases_4.0 6996 non-null uint8
18 Prior_purchases_5.0 6996 non-null uint8
19 Prior_purchases_6.0 6996 non-null uint8
20 Prior_purchases_7.0 6996 non-null uint8
21 Prior_purchases_8.0 6996 non-null uint8
22 Prior_purchases_10.0 6996 non-null uint8
dtypes: float64(3), uint8(20)
memory usage: 355.3 KB
test.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4000 entries, 0 to 3999
Data columns (total 23 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Customer_care_calls 4000 non-null float64
1 Cost_of_the_Product 4000 non-null float64
2 Weight_in_gms 4000 non-null float64
3 Warehouse_block_B 4000 non-null uint8
4 Warehouse_block_C 4000 non-null uint8
5 Warehouse_block_D 4000 non-null uint8
6 Warehouse_block_F 4000 non-null uint8
7 Product_importance_low 4000 non-null uint8
8 Product_importance_medium 4000 non-null uint8
9 Mode_of_Shipment_Road 4000 non-null uint8
10 Mode_of_Shipment_Ship 4000 non-null uint8
11 Customer_rating_2 4000 non-null uint8
12 Customer_rating_3 4000 non-null uint8
13 Customer_rating_4 4000 non-null uint8
14 Customer_rating_5 4000 non-null uint8
15 Prior_purchases_3.0 4000 non-null uint8
16 Prior_purchases_3.5 4000 non-null uint8
17 Prior_purchases_4.0 4000 non-null uint8
18 Prior_purchases_5.0 4000 non-null uint8
19 Prior_purchases_6.0 4000 non-null uint8
20 Prior_purchases_7.0 4000 non-null uint8
21 Prior_purchases_8.0 4000 non-null uint8
22 Prior_purchases_10.0 4000 non-null uint8
dtypes: float64(3), uint8(20)
memory usage: 172.0 KB
from sklearn.neural_network import MLPClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.gaussian_process.kernels import RBF
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import classification_report
from sklearn.model_selection import cross_val_score
from sklearn.metrics import roc_auc_score , plot_roc_curve, accuracy_score
from xgboost import XGBClassifier
from sklearn import metrics
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
import xgboost as xgb
from sklearn.model_selection import GridSearchCV
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33)
rf= RandomForestClassifier()
ad = AdaBoostClassifier(base_estimator =rf)
dt = DecisionTreeClassifier()
kn = KNeighborsClassifier()
lr = LogisticRegression(random_state= 43, solver='lbfgs', max_iter=1000)
rbf = RBF()
gp = GaussianProcessClassifier(1.0 * RBF(1.0))
mlp = MLPClassifier(alpha=1, max_iter=1000)
gnb = GaussianNB()
svc = SVC(random_state = 43, C = 10, gamma = 0.1, kernel ='rbf')
models = [rf,ad, dt, kn, svc, mlp, lr, gnb, svc]
for model in models:
model.fit(X_train, y_train)
pre = model.predict(X_test)
scores = cross_val_score(model, X_test, y_test, cv=5).mean().round(3)
#f1score = metrics.f1_score(y_test, y_pred).round(3)
print(model, '\n', 'Accuracy:', scores, '\n')
RandomForestClassifier()
Accuracy: 0.663
AdaBoostClassifier(base_estimator=RandomForestClassifier())
Accuracy: 0.668
DecisionTreeClassifier()
Accuracy: 0.628
KNeighborsClassifier()
Accuracy: 0.65
SVC(C=10, gamma=0.1, random_state=43)
Accuracy: 0.667
MLPClassifier(alpha=1, max_iter=1000)
Accuracy: 0.675
LogisticRegression(max_iter=1000, random_state=43)
Accuracy: 0.658
GaussianNB()
Accuracy: 0.626
SVC(C=10, gamma=0.1, random_state=43)
Accuracy: 0.667
pre = mlp.predict(test)
result = pd.read_csv("sampleSubmission.csv")
result['Reached.on.Time_Y.N'] = pre
result.to_csv('mlp2021-06-20_1.csv', index =False)
test.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4000 entries, 0 to 3999
Data columns (total 23 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Customer_care_calls 4000 non-null float64
1 Cost_of_the_Product 4000 non-null float64
2 Weight_in_gms 4000 non-null float64
3 Warehouse_block_B 4000 non-null uint8
4 Warehouse_block_C 4000 non-null uint8
5 Warehouse_block_D 4000 non-null uint8
6 Warehouse_block_F 4000 non-null uint8
7 Product_importance_low 4000 non-null uint8
8 Product_importance_medium 4000 non-null uint8
9 Mode_of_Shipment_Road 4000 non-null uint8
10 Mode_of_Shipment_Ship 4000 non-null uint8
11 Customer_rating_2 4000 non-null uint8
12 Customer_rating_3 4000 non-null uint8
13 Customer_rating_4 4000 non-null uint8
14 Customer_rating_5 4000 non-null uint8
15 Prior_purchases_3.0 4000 non-null uint8
16 Prior_purchases_3.5 4000 non-null uint8
17 Prior_purchases_4.0 4000 non-null uint8
18 Prior_purchases_5.0 4000 non-null uint8
19 Prior_purchases_6.0 4000 non-null uint8
20 Prior_purchases_7.0 4000 non-null uint8
21 Prior_purchases_8.0 4000 non-null uint8
22 Prior_purchases_10.0 4000 non-null uint8
dtypes: float64(3), uint8(20)
memory usage: 172.0 KB
dt.feature_importances_
array([0.05672293, 0.23272525, 0.41195796, 0.01805529, 0.01502322,
0.01478537, 0.02090981, 0.02145708, 0.01228093, 0.0170925 ,
0.01964704, 0.02609024, 0.01999404, 0.01998863, 0.01562156,
0.01670651, 0.01632885, 0.01580142, 0.01437632, 0.00774267,
0.00251584, 0.00172337, 0.00245318])








"스마트인재개발원에서 진행된 수업내용입니다"
스마트인재개발원
4차산업혁명시대를 선도하는 빅데이터, 인공지능, 사물인터넷 전문 '0원' 취업연계교육기관
www.smhrd.or.kr