(광주인공지능학원)3차프로젝트 MFCC 복습하기
Voice can combine what people say and how they say it by two-factor authentication in a single action. Other identifications like fingerprints, handwriting, iris, retina, face scans can also help in biometrics but voice identification is needed as an authentication that is both secure and unique. Voice can combine two factors, namely, personal voice recognition and telephone recognition. Voice recognition systems are cheap and easily understood by users. In today's smart world, voice recognition plays a very critical role in many aspects. Voice based banking, home automation and voice recognition based gadgets are some of the many applications of voice recognition
Mel frequency Cepstral coefficients algorithm is a technique which takes voice sample as inputs. After processing, it calculates coefficients unique to a particular sample. In this project, a simulation software called MATLAB R2013a is used to perform MFCC. The simplicity of the procedure for implementation of MFCC makes it most preferred technique for voice recognition.

MFCC (Mel-Frequency Cepstral Coefficient)
음성인식에서 MFCC, Mel-Spectrogram는 빼놓고 얘기할 수 없는 부분이다.
그렇다면 MFCC, Mel-Spectrogram란 무엇인지 알아보자.
간단히 말하면, MFCC는 '음성데이터'를 '특징벡터' (Feature) 화 해주는 알고리즘이다.
HAMMING WINDOW Each frame has to be multiplied with a hamming window in order to keep the continuity of the first and the last points in the frame. If the signal in a frame is denoted by x(n), n = 0,…N-1, then the signal after Hamming windowing is, x(n) * w(n) (3) where w(n) is the Hamming window defined by w(n) = 0.54 - 0.46 * cos (2πn/(N-1)) (4) where 0 ≤ n ≤ N-1

D.FAST FOURIER TRANSFORM Spectral analysis shows that different timbres in speech signals corresponds to different energy distribution over frequencies. Therefore FFT is performed to obtain the magnitude frequency response of each frame. When FFT is performed on a frame, it is assumed that the signal within a frame is periodic, and continuous when wrapping around. If this is not the case, FFT can still be performed but the discontinuity at the frame's first and last points is likely to introduce undesirable effects in the frequency response. To deal with this problem, we multiply each frame by a hamming window to increase its continuity at the first and last points.[3]
E.TRIANGULAR BANDPASS FILTERS The magnitude frequency response is multiplied by a set of 40 triangular band pass filters to get the log energy of each triangular band pass filter. The positions of these filters are equally spaced along the Mel frequency. From centre frequencies from 133.33 Hz to 1 kHz, there are 13 overlapping (50%) linear filters, while for centre frequencies from 1 kHz to 8 kHz there are 27 overlapping filters spaced logarithmically.

MFCC를 알기 위해서 먼저 Mel이 뭔지를 알아야 한다.
Mel은 사람의 달팽이관을 모티브로 따온 값이라고 생각하면 된다!
기계에게 음성을 인식시키기 전에, 사람은 어떤 식으로 음성을 인식하는지를 살펴보자.
F.DISCRETE FOURIER TRANSFORM In this step, DCT is applied to the output of the N triangular bandpass filters to obtain L mel-scale cepstral coefficients. The formula for DCT is, C(n) = ∑ Ek * cos(n * (k - 0.5) * π/40 )) (5) where n = 0,1,..to N where N is the number of triangular bandpass filters, L is the number of mel-scale cepstral coefficients. In this project, there are N = 40 and L = 13. Since we have performed FFT, DCT transforms the frequency domain into a time-like domain called quefrency domain. The obtained features are similar to cepstrum, thus it is referred to as the mel-scale cepstral coefficients, or MFCC. MFCC alone can be used as the feature for speech recognition.
A. RECORDING AND SAMPLING The recorded speech signals are sampled and stored using Audacity. The sampling is done at a rate of 16000 samples per second. Each speech signal is divided into windows of 16 ms each and hence, 256 samples each. MFCC is implemented for each of these windows and a set of parameters is extracted per window. The first window consists of first 256 samples. The second window overlaps half of the first window and consists of 128 samples of the first window and 128 samples after it. Hence a 50% overlap is used. It is observed that the same speaker saying the same word at two different instants have many variations. So it is important to calculate of the coefficients which almost remain same for a speaker at different instants becomes important. B.MEL FILTER BANK There are 40 Mel filters that form Mel filter Bank. Each filter passes a particular set of frequencies corresponding to samples from a frame. For a 256 sample frame, the filter bank spreads over 128 samples only because the FFT is symmetric. C. MEL FREQUENCY CEPSTRAL COEFFICIENTS Voice samples of two speakers saying the same word "HELLO" at two different instants were passed through the MFCC algorithm and their respective MFCC Coefficients were extracted, considering two voice samples per speaker, that is one that is stored as template in the database and the other is real time input.

사람은 소리를 달팽이관을 통해 인식한다.
그럼 달팽이관은 어떤 식으로 소리를 인식할까??
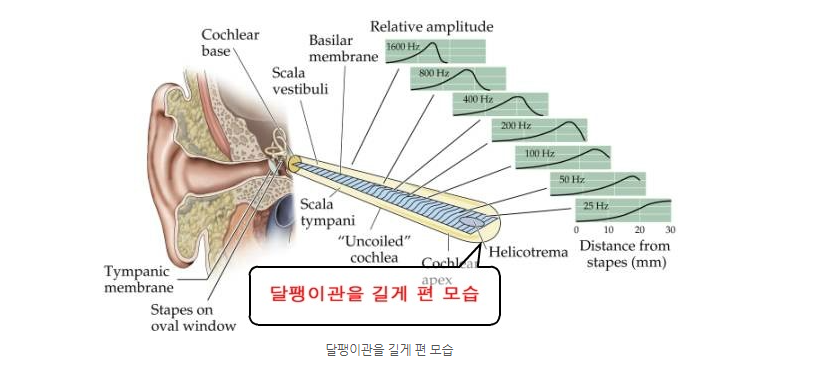
달팽이관을 똘똘 말려있지만, 실제로 길게 펴서 보면 달팽이관의
각 부분은 각기 다른 진동수(주파수)를 감지한다.
이 달팽이관이 감지하는 진동수를 기반으로 하여 사람은 소리를 인식한다.
그렇기 때문에 이 주파수(Frequency)를 Feature로 쓰는 것은 어떻게 보면 당연한 얘기이다.
하지만, 달팽이관은 특수한 성질이 있다.
주파수가 낮은 대역에서는 주파수의 변화를 잘 감지하는데,
주파수가 높은 대역에서는 주파수의 변화를 잘 감지하지 못한다는 것이다.
예를 들어, 실제로 사람은 2000Hz에서 3000Hz로 변하는 소리는 기가막히게 감지하는데,
12000Hz에서 13000Hz로 변하는 소리는 잘 감지를 하지 못한다.
이 이유를 달팽이관의 구조로 살펴보면, 달팽이관에서 저주파 대역을 감지하는 부분은 굵지만
고주파 대역을 감지하는 부분으로 갈수록 얇아진다
그렇다면, 특징벡터로 그냥 주파수를 쓰기 보다는
이러한 달팽이관의 특성에 맞춰서 특징을 뽑아주는 것이
더욱 효과적인 피쳐를 뽑는 방법일 것이다.
그래서 위와 같이 사람 달팽이관 특성을 고려한 값을 Mel-scale이라고 한다.
Pre-Emphasis
간단히 말하면 High-pass Filter이다.
사람이 발성 시 몸의 구조 때문에 실제로 낸 소리에서
고주파 성분은 많이 줄어들게 되서 나온다고 한다.
(이게 본인이 생각하는 본인 목소리와 다른 사람이 생각하는 본인 목소리가 다른 이유라고 한다)
그래서 먼저 줄어든 고주파 성분을 변조가 강하게 걸리도록 High-pass Filter를 적용해주는 과정이다.
Sampling and Windowing
Pre-emphasis 된 신호에 대해서 앞에서 언급했던 이유 때문에
신호를 20~40ms 단위의 프레임으로 분할한다.
여기서 주의할 점은, 이 때 프레임을 50%겹치게 분할한다는 것이다.

프레임끼리 서로 뚝뚝 떨어지는 것이 아니라 프레임끼리
연속성을 만들어주기 위해 프레임을 50% 겹치게 분할한다.
(물론 겹치는 정도는 조정가능한 파라미터이다)
왜 연속성이 필요한지 궁금할 수 있다.
만약 프레임이 서로 뚝뚝 떨어지게 샘플링을 한다면, 프레임과 프레임의 접합 부분에서
순간 변화율이 ∞ (무한대) 가 될 수 있다. 이러한 부분을 방지하기 위한 과정이다.
Fast Fourier Transform
각각의 프레임들에 대하여 Fourier Transform을 통하여 주파수 성분을 얻어낸다.
여기 FFT 까지만 적용하더라도 충분히 학습 가능한 피쳐를 뽑을 수 있다.
하지만 사람 몸의 구조를 고려한 Mel-Scale을 적용한 feature가 보통
더 나은 성능을 보이기 때문에 아래의 과정을 진행한다.
Mel Filter Bank
가장 중요한 부분이다.
각각의 프레임에 대해 얻어낸 주파수들에 대해서 Mel 값을 얻어내기 위한 Filter를 적용한다.

광주인공지능학원 3차프로젝트를 위한 마지막 복습 내일이면 광주인공지능학원 마지막 날이다..
사실 서운하기도하고 광주인공지능학원에서 정들었던 우리팀원들 1차 2차 3차 ..ㅠㅠ 눈물이 좀 난다.
광주인공지능학원은 마지막 장관님까지 오셔서 참관을 하시는데 정말 우리팀원들을 위해서라도 잘 해야겠다는 생각이 든다.
광주인공지능학원의 마지막 발표영상은 따로 발표가 끝난 후에 업로드할 예정이다.
광주인공지능학원의 임명진쌤도 많이 고생하셨는데 또 볼날이 있기를 기대해본다.
광주인공지능학원을 위하여!
"스마트인재개발원에서 진행된 수업내용입니다"
스마트인재개발원
4차산업혁명시대를 선도하는 빅데이터, 인공지능, 사물인터넷 전문 '0원' 취업연계교육기관
www.smhrd.or.kr