
광주인공지능학원 스마트인재개발원에서의 3차프로젝트가 시작
우리팀은 아이의 움직임으로 생체징후 뒤집기를 파악하고,
방안 소리를 (조용함, 시끄러움, 울음, 웃음)
아이의 울음소리는 총 5가지 (고통, 트림, 배고픔, 불편함, 피곤함)으로 분류하려고 한다.
데이터는 수집량이 부족해서
4개의 전처리를 하였다.
①Adding white Noise
②Shfting the Sound
③Streching the Sound
④Reverse the sound
import pandas as pd
import librosa
import numpy as np
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from keras.layers import Conv1D, MaxPool1D, Conv2D, Activation, MaxPool2D, Flatten, Conv3D,MaxPool3D , GlobalAveragePooling2D
from tqdm import tqdm
import librosa.display
import os
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
from scipy.io import wavfile as wav
from sklearn.preprocessing import LabelEncoder
from keras.utils.np_utils import to_categorical
from sklearn.model_selection import train_test_split
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from keras.optimizers import Adam
from keras.utils import np_utils
from sklearn import metrics
from keras.callbacks import ModelCheckpoint
from datetime import datetime
from tensorflow.keras.models import load_model방안의 데이터 로딩
audio_dataset_path ='room_data'
metadata=pd.read_csv('room_data/result.csv')metadata
데이터 시각화
filename_list = ['room_data/fold1/cry1.wav', 'room_data/fold2/noise1.wav', 'room_data/fold3/silence1.wav', 'room_data/fold4/laugh1.wav']
plt.figure(figsize=(12,4))
data,sample_rate = librosa.load(filename_list[0])
_ = librosa.display.waveplot(data, sr = sample_rate)
<cry>

<noise>

<slience>

<laugh>
## 스테레오 타입의 데이터를 두 채널의 평균값을 이용하여 하나로 병합하고, 모노 타입으로 변환해 주었다.
filename = 'room_data/fold1/cry1.wav'
librosa_audio, librosa_sample_rate = librosa.load(filename)
scipy_sample_rate, scipy_audio = wav.read(filename)
print('Original sample rate:', scipy_sample_rate)
print('Librosa sample rate:', librosa_sample_rate)일단 스트레오타입의 평균값을 이용했다. 모노타입과 스트레오 타입을 비교해보자

rate는 위와 같고
plt.figure(figsize=(12, 4))
plt.plot(scipy_audio)
# 합쳐진 채널
plt.figure(figsize=(12, 4))
plt.plot(librosa_audio)
# 다양하게 분포했던 Sample Rate 값들을 표준화 시켜주는 작업을 수행했다.
# Sample-rate conversion 기술을 활용하여 다양한 Sample Rate들을 표준화 시켰다.
# Sample-rate conversion? 이산신호의 샘플링 속도를 변경하여 기본 연속 신호의 새로운 이산 표현을 얻는 과정
# Librosa 모듈의 load 기능을 이용하여 데이터들의 Sample Rate를 22.05KHz로 변환했다.# librosa 모듈의 load 기능을 이용하여 각 데이터들의 Bit Depth를 -1 과 1 사이의 값을 갖도록 정규화

여기서 광주인공지능학원 이상준 선생님의 도움을 받았다
# 소리데이터는 다른 비정형 데이터와는 다르게 주파수 및 시계열의 특성을 모두 분석한 feature가 필요했다.
# 여러번의 실패를 맛보고, 광주인공지능학원 팀원들과 열심히 공부한 결과 MFCC 알고리즘을 활용해서 Feature를 추출해주어야 한다는 점을 알게 되었다.
# 데이터셋 path 지정
audio_dataset_path ='room_data'
matadata=pd.read_csv('room_data/result.csv')
# 각 소리에 대해 feature를 추출
features = []
for index, row in metadata.iterrows():
file_name = os.path.join(os.path.abspath(audio_dataset_path), 'fold' + str(row["fold"])+'\\', str(row["slice_file_name"]))
class_label = row["class"]
data = extract_features(file_name)
features.append([data, class_label])
# df로 만들기
featuresdf = pd.DataFrame(features, columns=['feature','class_label'])print('Finished feature extraction from ', len(featuresdf), ' files')
print('Max :',max)
librosa.display.specshow(mfccs, sr = librosa_sample_rate, x_axis = 'time')
X = np.array(featuresdf.feature.tolist())
y = np.array(featuresdf.class_label.tolist())
le = LabelEncoder()
yy = to_categorical(le.fit_transform(y))num_labels = yy.shape[1]
filter_size = 2
# Construct model
model = Sequential()
model.add(Dense(256, input_shape=(40,)))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_labels))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='adam')
model.summary()일단 MLP로 돌려보았다.
# 모델 선정 이유
# 신경망의 기본이 되는 모델로서, 입력층, 은닉층, 출력층의 단순한 구조로 구현이 용이하여 학습 소요시간이 짧으므로 채택
# 지도학습이 필요한 문제를 해결하는데 주로 사용되며, 음성인식 혹은 이미지 인식에서 주로 사용되기 때문에 사용
# 모델 구현
num_labels = yy.shape[1]
filter_size = 2
# Construct model
model = Sequential()
model.add(Dense(256, input_shape=(40,)))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_labels))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='adam')
model.summary()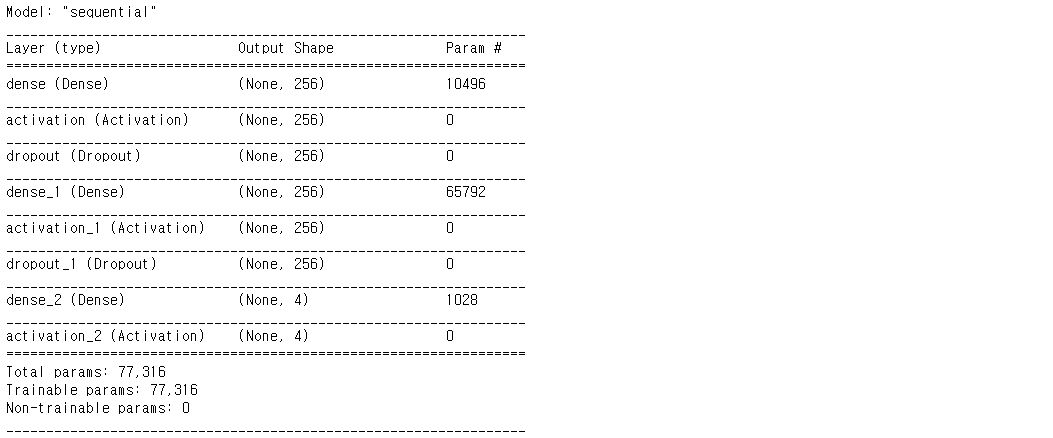
num_epochs = 100
num_batch_size = 32
# 얘 원래 있는 모델을 쓰는게 맞는지
checkpointer = ModelCheckpoint(filepath='C:/code/cap_sound/save_models/weights.best.basic_mlp.hdf5',
verbose=1, save_best_only=True)
start = datetime.now()
model.fit(x_train, y_train, batch_size=num_batch_size, epochs=num_epochs, validation_data=(x_test, y_test), callbacks=[checkpointer], verbose=1)
duration = datetime.now() - start
print("Training completed in time: ", duration)
과적합없이 잘 나오는 걸 볼 수 있다 그런데 MFCC자체가 시계열 데이터고 MLP는 부적합 할 수 있다고 생각해서 광주인공지능학원팀원들과 열심히 연구해보았다.
2. 합성곱 신경망 (Convolutional Neural Network, CNN)
CNN은 필터링 기법을 인공신경망에 적용함으로써 이미지를 더욱 효과적으로 처리하기 위해 처음 소개되었으며, 현재 딥 러닝에서 이용되고 있는 형태의 CNN이 제안되었다. 기존의 필터링 기법은 그림 1과 같이 고정된 필터를 이용하여 이미지를 처리했다. CNN의 기본 개념은 "행렬로 표현된 필터의 각 요소가 데이터 처리에 적합하도록 자동으로 학습되게 하자"는 것이다. 예를 들어, 이미지를 분류 알고리즘을 개발하고자 할 때 우리는 필터링 기법을 이용하여 분류 정확도 향상시킬 수 있을 것이다. 그러나 한 가지 문제점은 사람의 직관이나 반복적인 실험을 통해 알고리즘에 이용될 필터를 결정해야 한다는 것이다. 이러한 상황에서 CNN을 이용한다면, 알고리즘은 이미지 분류 정확도를 최대화하는 필터를 자동으로 학습할 수 있다.
2.1. CNN의 구조
일반적인 인공신경망은 그림 2와 같이 affine으로 명시된 fully-connected 연산과 ReLU와 같은 비선형 활성 함수 (nonlinear activation function)의 합성으로 정의된 계층을 여러 층 쌓은 구조이다.
CNN (Convolutional Nural Network)
모델 선정 이유
단순한 MLP의 확장이지만, 입력층, 컨볼루션층, 폴링층, 완전연결계층이 결합된 형태로 대부분의 경우 MLP보다 더 좋은 성능기대해본다.
광주인공지능학원 스마트인재개발원에서 '케라스 창시자에게 배우는 딥러닝' 책을 지원해주었다.

또한 광주인공지능학원 스마트인재개발원에서 라즈베리파이 키트를 지원해주었다.
다음글에서는 CNN모델 설계와 멀티쓰레딩에 대해 알아보려한다.
우리 프로젝트는 총 2번의 딥러닝이 구동해야하고, 레코딩과 판단이 같이 이루어져야하기 때문에 파이썬의 멀티쓰레드 기능이 필수적이다.
광주인공지능학원 스마트인재개발원에서의 마지막 프로젝트가 2주 남았다. 남은시간 열심히해서 좋은 결과를 얻고 싶다.
"스마트인재개발원에서 진행된 수업내용입니다"
스마트인재개발원
4차산업혁명시대를 선도하는 빅데이터, 인공지능, 사물인터넷 전문 '0원' 취업연계교육기관
www.smhrd.or.kr
'스마트 인재개발원 > 3차프로젝트' 카테고리의 다른 글
| (광주인공지능학원) 3차프로젝트 안드로이드 어플리케이션 만들기 및 논문분석 (0) | 2021.08.22 |
|---|---|
| (광주인공지능학원) 3차프로젝트 멀티쓰레드 설계 및 울음소리 분석 (0) | 2021.08.22 |
| (광주인공지능학원) 3차프로젝트 파이썬 멀티쓰레드 & CNN 신생아 울음소리 분석(2) (0) | 2021.08.15 |
| (광주인공지능학원) Skeleton Vector Information and RNN Learning Algorithm 공부하기 (0) | 2021.08.01 |
| (광주인공지능학원) 3차 프로젝트 MFCC Deep Learning 기반의 음성인식 공부 (0) | 2021.08.01 |